Eric C. Peterson

I am a mathematician and programmer, working in some intersection or another or these two fields. Presently, I'm working on compilation problems at OpenAI, where I was also a previously a Fellow thinking about active learning. Before this, I've worked on control electronics design for quantum computing at AWS, on quantum compilation at IBM Research and at Rigetti Computing, and on (chromatic) homotopy theory in academia. In addition to "traditional" research, I am very interested in communication within scientific circles. I used to spend a lot of time coaxing my topologist peers to speak the language of number theory.
My tour in academia consisted of a Benjamin Peirce postdoctoral fellowship in the Harvard math department, graduate work at Berkeley under Constantin Teleman, and undergraduate studies in computer science at Urbana-Champaign under Matt Ando and Elsa Gunter.
This URL used to host a group research blog, Chromotopy.
Writing
My mathematical interests are in using algebro-geometric tools to answer questions in algebraic topology, and I have a penchant for computations—but I've done some other things too.
Papers
-
Distributed online decoding for large-scale quantum computers, with Peter J. Karalekas.
In preparation . -
p-adic congruences in iterated derivatives of ℘, with Kiran Luecke.
Submitted ,June 9, 2025 . -
GPT-4.5 system card, with OpenAI.
Online only ,February 27, 2025 . -
GPT-4o system card, with OpenAI.
arXiv only ,October 25, 2024 . -
Hardware-efficient quantum error correction using concatenated bosonic qubits, with Harald Putterman et al.
Nature ,638, 927–934 (2025) . -
Demonstrating a long-coherence dual-rail erasure qubit using tunable transmons, with Harry Levine et al.
Physical Review X ,v. 14 (2024) 011051 . -
Spatially parallel decoding for multi-qubit lattice surgery, with Sophia Lin, Krishanu Sankar, and Prasahnt Sivarajah.
Accepted to Quantum Science and Technology ,November 19, 2023 . -
A distributed blossom algorithm for minimum-weight perfect matching, with Peter J. Karalekas.
arXiv ,October 17, 2022 . -
Techniques for combining fast local decoders with global decoders under circuit-level noise, with Christopher Chamberland, Luis Goncalves, Prasahnt Sivarajah, and Sebastian Grimberg.
Quantum Science and Technology ,v. 8 (2023) 045011 . -
There aren't that many Morava E-theories, with Kiran Luecke.
Submitted ,February 9, 2022 . -
Optimal synthesis into fixed XX interactions, with Lev S. Bishop and Ali Javadi-Abhari.
Quantum ,v. 6 (2022) 696 . -
aether: Distributed system simulation in Common Lisp, with Peter J. Karalekas.
Proceedings of the European Lisp Symposium ,v. XIV (2021) 54-62 . -
An open-source, industrial-strength optimizing compiler for quantum programs, with Erik J. Davis, Mark G. Skilbeck, and Robert S. Smith.
Quantum Science and Technology ,v. 5 (2020) 044001 . -
A quantum-classical cloud platform optimized for variational hybrid algorithms, with Peter J. Karalekas, Nikolas A. Tezak, Colm A. Ryan, Marcus P. da Silva, and Robert S. Smith.
Quantum Science and Technology ,v. 5 (2020) 2 . -
Two-qubit circuit depth and the monodromy polytope, with Gavin E. Crooks and Robert S. Smith.
Quantum ,v. 4 (2020) 247 . -
Unsupervised machine learning on a hybrid quantum computer, with J. S. Otterbach et al.
arXiv ,December 15, 2017 . -
Coalgebraic formal curve spectra and spectral jet spaces.
Geometry & Topology ,v. 24 (2020) 1-47 . -
Cocycle schemes and MU[2k, ∞)-orientations.
Contemporary Mathematics ,v. 707 (2018) 77-88 . -
A relative Lubin–Tate theorem via higher formal geometry, with Aaron Mazel-Gee and Nathaniel Stapleton.
Algebraic and Geometric Topology ,v. 15 (2015) 2239-2268 . -
A 2-local classification of symmetric multiplicative 2-cocycles, with Adam Hughes and JohnMark Lau.
Journal of Pure and Applied Algebra ,v. 217 (2013) 393-408 . -
A classification of symmetric 2-cocycles, with Adam Hughes and JohnMark Lau.
Illinois Journal of Mathematics ,v. 53.4 (2009) 983-1017 .
Expository writing
-
Formal Geometry and Bordism Operations.
Course notes, now available as a book through Cambridge University Press . -
Barsotti–Tate groups and Dieudonné crystals.
English translation of Alexandre Grothendieck's 1974 original . -
On certain groups of unitary operators.
English translation of Andre Weil's 1964 original . -
Topology from an algebraic viewpoint.
Course notes from Harvard 231b in 2017, quite unpolished . -
MIT E-theory Conjectures Seminar notes, with Mark Behrens, Drew Heard, Mike Hopkins, Geoffroy Horel, Tyler Lawson, Jacob Lurie, Tomer Schlank, Nat Stapleton, and Sebastian Thyssen.
Transcript of contributed talks to the 2013 spring seminar ,August 14th, 2013 . -
Vector Fields on Spheres, etc., with Haynes Miller and Matt Ando, course notes.
In preparation ,incomplete draft available; rife with typos and poor typesetting, and missing spectral sequence diagrams. See also: Haynes-Notes github repository, as well as Haynes's revision . -
Computations with spectral sequences.
Barely started book project .
I passed my qualifying exam on November 23rd, 2011. Here are my qual syllabus and transcript of the exam questions I could remember.
Here is an unedited copy of my PhD thesis. Beware: this document contains several significant errors. Readers should consult the published version for the original research and the book project for the exposition. A long time ago, I wrote an undergraduate thesis under Elsa Gunter, where we explored a modification of ambient process calculi. Unfortunately, the main technical result remains unfinished.
I'm not very active, but I have also written some things on MathOverflow.
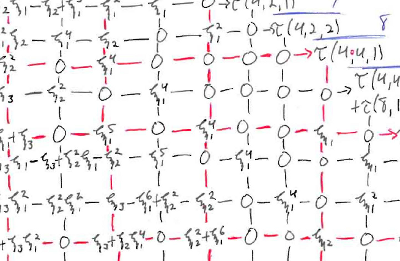
Also, here are two animations of the stabilization of the unstable Adams spectral sequence for the sphere, at the prime 2 and at the prime 3, due to Barnes, Poduska, and Shick.
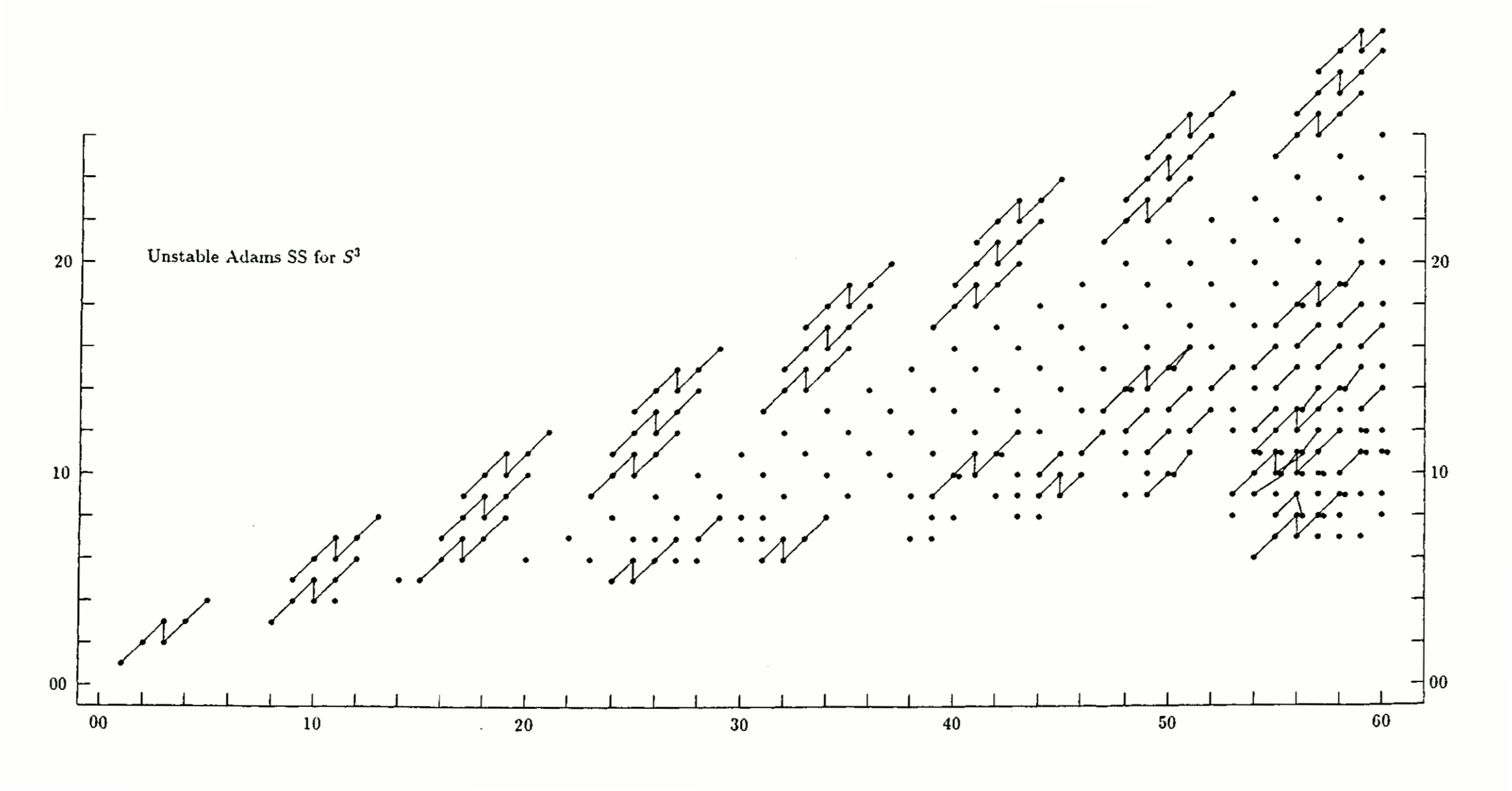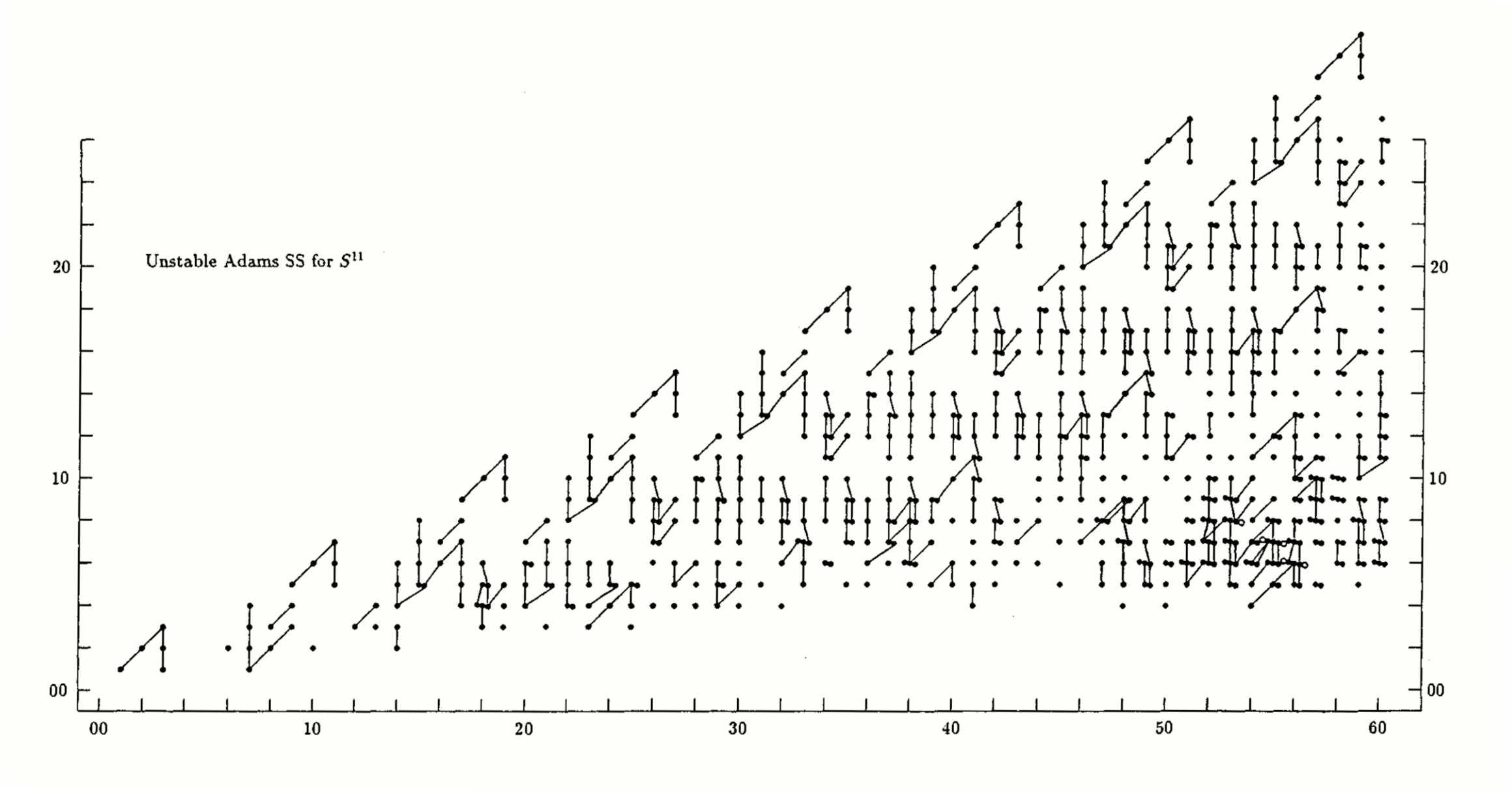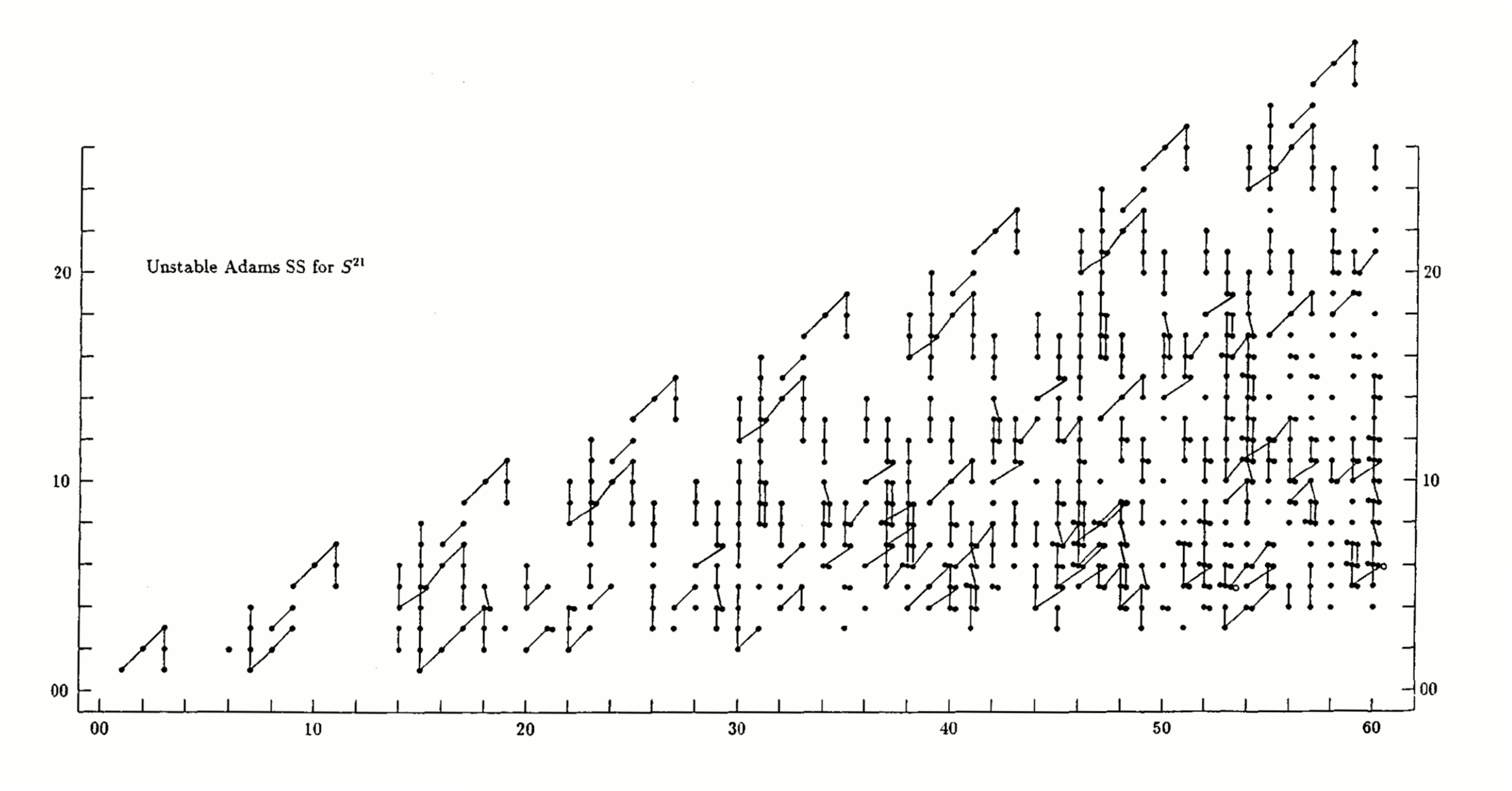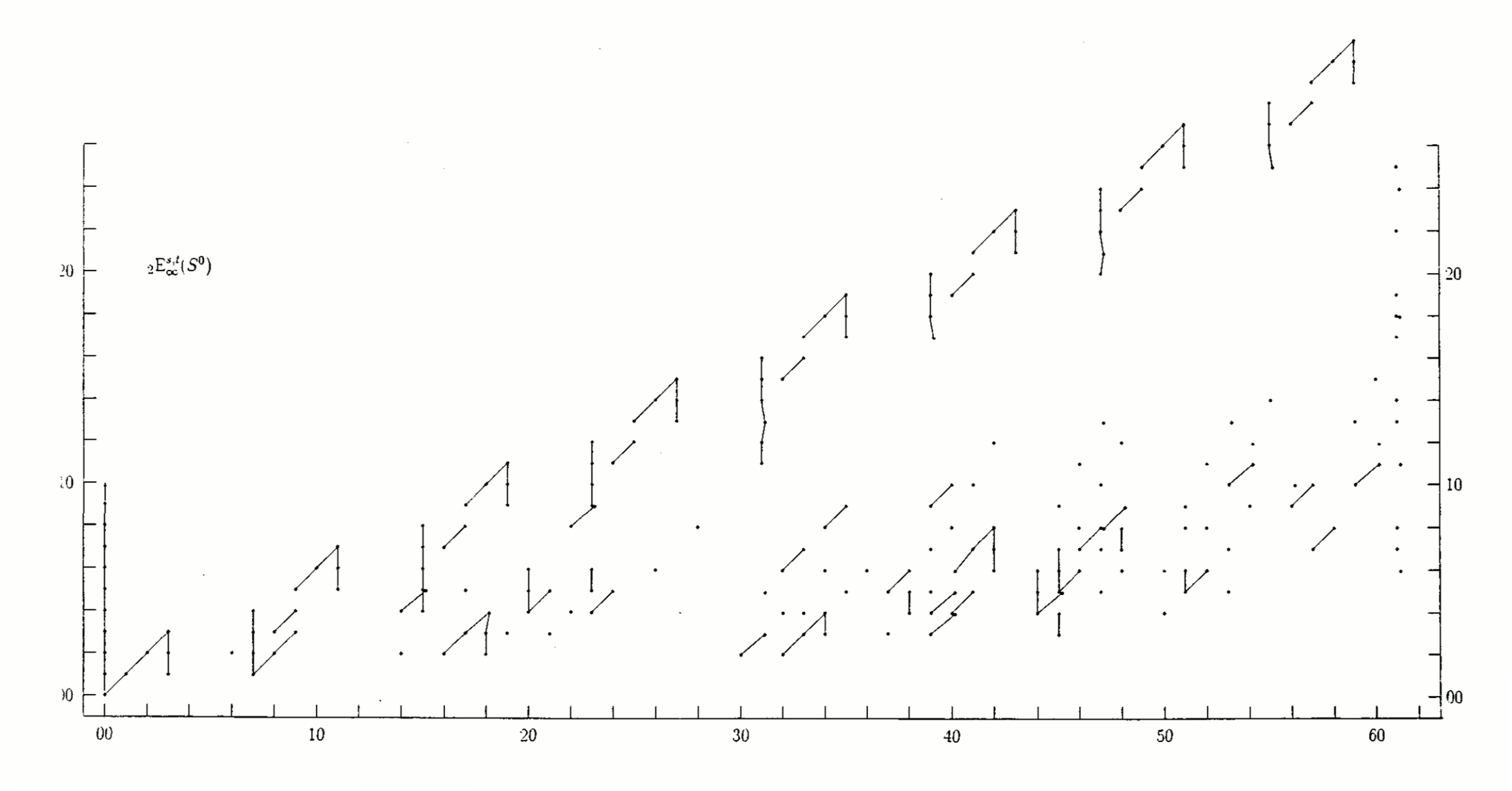{kind=link}
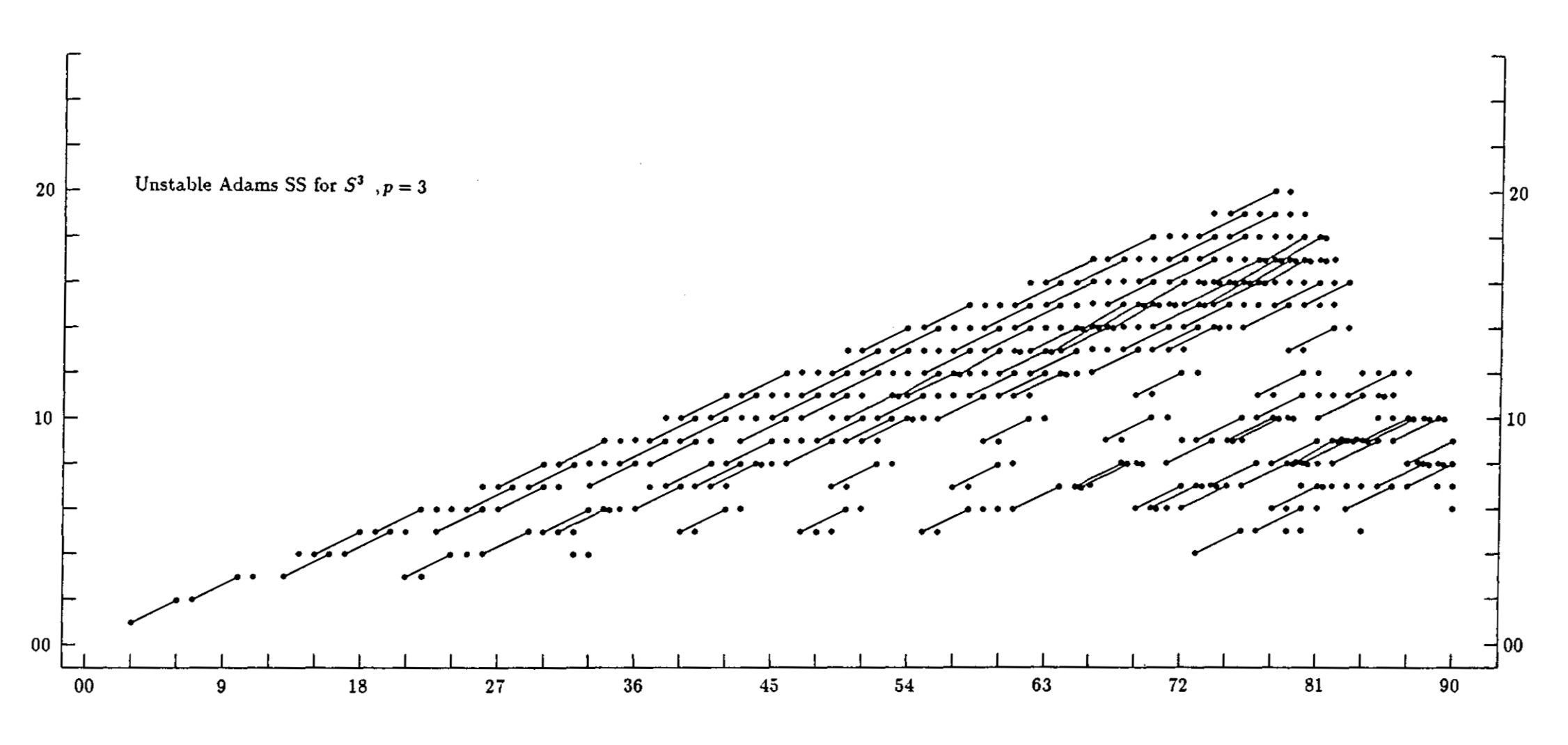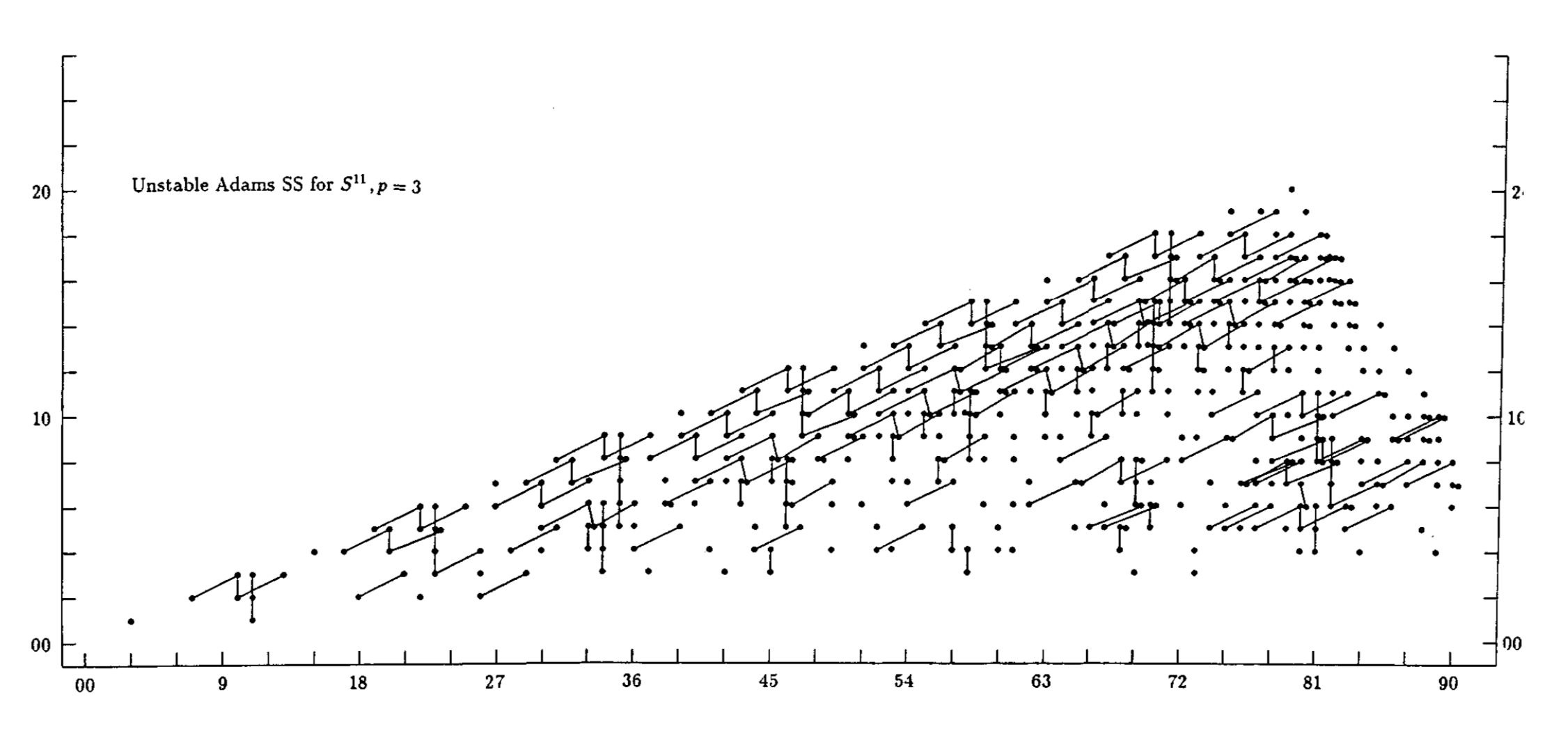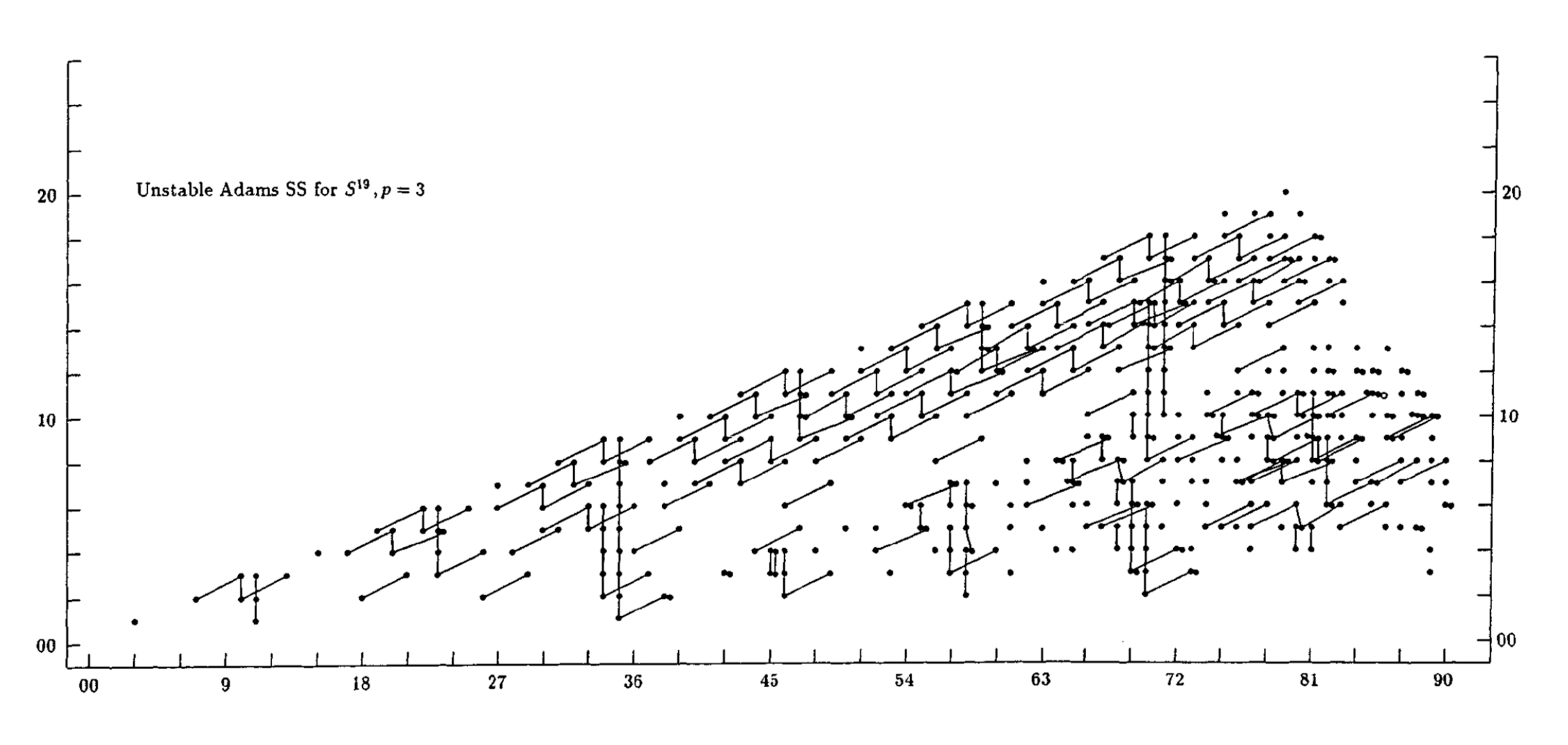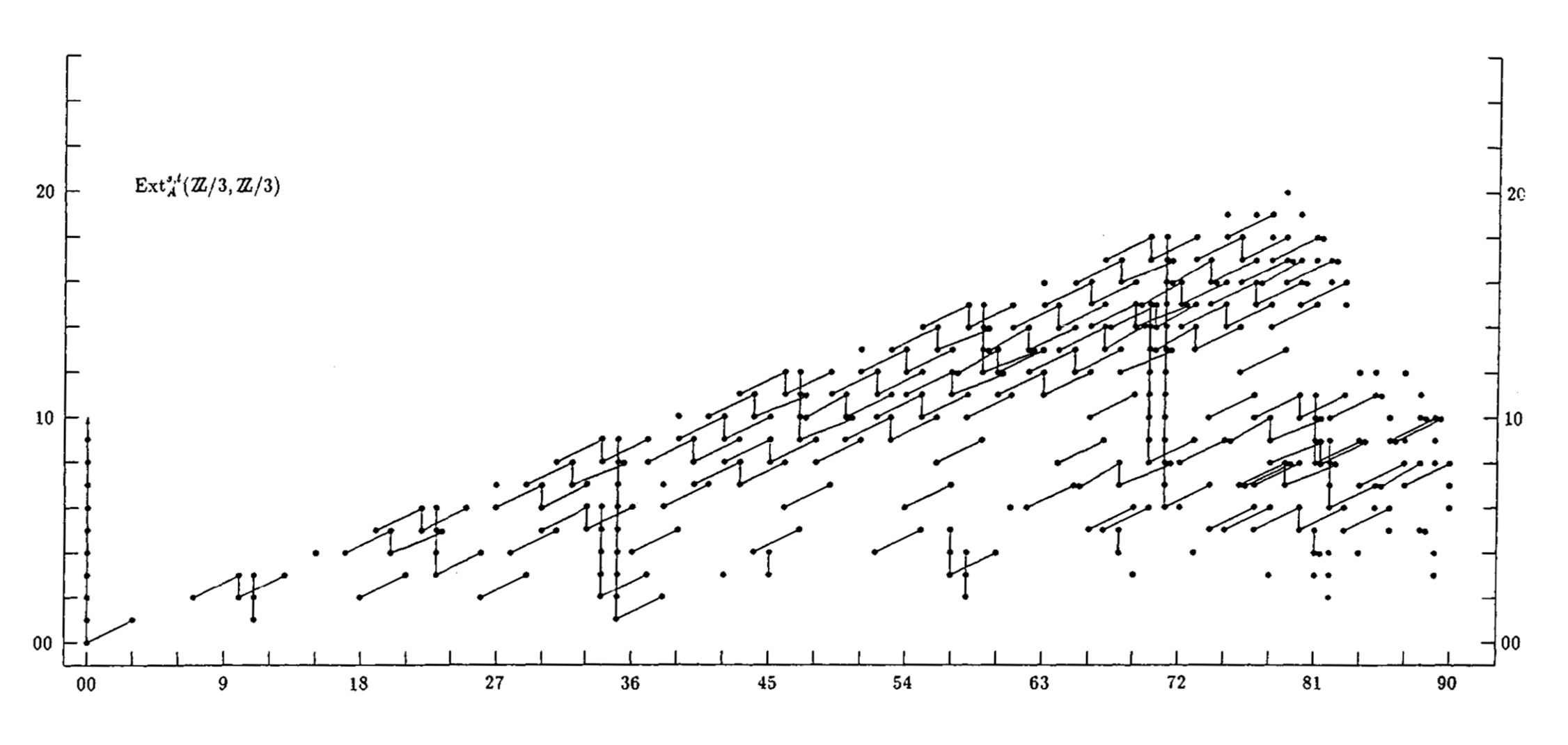{kind=link}
Speaking
I've given a good number of talks, and I was often funded through a teaching position. Students and onlookers can find both talk notes and course pages below.
Slides, talk notes, reports
-
Gateset design for contemporary systems.
Alibaba QCS Seminar ,January 13, 2022. (video) . -
aether: Distributed system emulation in Common Lisp.
European Lisp Symposium XIV ,May 4, 2021. (video) . -
Two-qubit circuits and the monodromy polytope.
3rd International Workshop on Quantum Compilation ,November 7, 2019 . -
quilc: The Rigetti Quil compiler.
IBM ,August 16, 2019 . -
Faithful-ish algebraic models for homotopy theory.
Gammage Seminar ,July 12th, 2018 . -
Robert Langlands: Abel Laureate 2018.
Tuesday Technical Seminar at Rigetti ,May 1st, 2018. (slides) . -
Topological modular forms: Construction and computation.
European Talbot Workshop on Dualities in Algebra, Geometry, and Topology ,June 15th, 2017 . -
Efficient occupation count for certain probabilistic fermionic motion.
Rigetti Computing ,May 10th, 2017 . -
Bordism: An introduction and sampler.
Graduate Student Topology & Geometry Conference ,April 2nd, 2016 . -
Spectra and G-spectra.
Juvitop ,September 23rd, 2015 . -
Introduction to E-theory.
Flavors of Cohomology workshop ,June 3rd-5th, 2015 . -
Some formal geometry around K-theory.
Stanford topology seminar ,October 29th, 2014 . -
Algebraic topology and algebraic number theory.
Graduate Student Topology and Geometry Conference ,April 5th, 2014 . -
Operadic Koszul duality.
Berkeley Koszul Duality seminar ,November 21st, 2013 . -
Determinantal K-theory and a few applications.
Johns Hopkins topology seminar ,November 11th, 2013 . -
Recurrences in Thom spectra.
xkcd seminar ,November 5th, 2013 . -
Arithmetic and complex bordism.
Pre-MSRI semester seminar at UC-Berkeley ,October 15th, 2013 . -
Spectra and stability.
Pre-MSRI semester seminar at UC-Berkeley ,September 10th, 2013 . -
Differentials in a May spectral sequence are topological.
MSRI workshop on algebraic topology ,June 28th, 2013 . -
The Morava K-theories of Eilenberg–Mac Lane spaces.
Talbot workshop on chromatic homotopy theory ,April 25th, 2013 . -
Tangent spaces for certain spectra.
UIUC topology seminar ,January 22nd, 2013 . -
BRST quantization of a relativistic point-particle, with Kevin Wray.
Mini-conference on quantum field theory ,December 3rd, 2012 . -
On Beyond Hatcher!.
Berkeley topology seminar ,November, 2012 . -
Taylor towers for homotopy functors.
Goodwillie Calculus Arbeitsgemeinschaft at Uni-Bonn ,April 19th, 2012 . -
Extraordinary homotopy groups.
xkcd seminar ,November 15th, 2011 . -
Spectral sequences from co/simplicial objects.
xkcd seminar ,September 20th, 2011 . -
Cotangent sums and the G-signature theorem.
Mini-conference on the Atiyah-Singer index theorem ,May 16th, 2011 . -
Morava E-theory of Eilenberg–Mac Lane spaces.
REGS project report ,August 2nd, 2010 . -
Group cohomology and topology: using slinkies to understand addition.
Pi Mu Epsilon talk ,February 18th, 2010 . -
Additive and multiplicative cocycles and Singer's calculation of the (co)homology of BU's connective covers.
AMS Special Session in Algebraic Topology held in honor of Bill Singer ,October 11th, 2008 .
Courses / sections taught
- Spring 2017: 231b: Advanced Algebraic Topology: main course website.
- Spring 2017: 25b: Honors Linear Algebra and Real Analysis II: main course website.
- Fall 2016: 25a: Honors Linear Algebra and Real Analysis I: main course website.
- Spring 2016: 130: Classical geometry: main course website.
- Spring 2016: 278: Formal geometry in bordism theory: main course website.
- Fall 2015: 1b: Calculus, Series, and Differential Equations with Prof. Gottlieb (email, website), section TBA: main course website, section website.
- Summer 2015: 53: Multivariate Calculus with Prof. Hutchings (email, website), section W: main course website, section website.
- Fall 2013: 55: Discrete Mathematics with Prof. Evans (email, website), section 109, 110: main course website, section website.
- Fall 2012: 1A: Calculus I with Prof. Borcherds (email, website), section 111, 113, 114: main course website, section website.
- Fall 2011: 53: Multivariate Calculus with Prof. Frenkel (email, website), section 205, 209: main course website, section website.
- Spring 2011: 54: Linear Algebra / Differential Equations with Prof. Gu (email, website), section 211, 212: main course website, section website.
- Fall 2010: 1B: Calculus II with Prof. Jones (email, website), section 210, 212: main course website, section website.
- Spring 2010: 231: Calculus II with Prof. Bronski (email, website), section BD5, BD6: main course website, section website.
- Fall 2009: 221: Calculus I with Prof. Leininger (email, website), section BD1, BD2: main course website, section website.
Software
| pmod_mtds: | |
| Pyrlang link protocol: | |
| monodromy: | |
| dTQEC: | |
| quilc: | |
| Atlas: | |
| Ext Chart: | |
| Op[]: | |
| Coact: | |
| A-cocycles: | |
| A-visual: | |
| M-cocycles: | |
| Persistent Sullivan models: | |
| Swift-Agenda: | |
| Agenda: | |
| Smithy: | |
| MW2: |
This is a work in progress.