This past summer I helped out a bit on an REU project, on extending a few results and conjectures from this paper. Those results/conjectures are both amazing and easy to describe (if not to prove), so I want to do that here. It’s also a nice excuse to talk about the story of reduced words for permutations.
Let be the transposition . A reduced word for a permutation is a sequence of integers such that and is minimal. That is, a reduced word is a minimal way of getting from to by repeatedly interchanging adjacent entries.
Examples
There are 2 reduced words for :
has 2 also: and .
A little thought will show that the length of a reduced word for is the same as the length of , the number of inversions in : pairs such that . It’s also not hard to see that reduced words always exist, i.e. that the symmetric group is generated by adjacent transpositions.
The element of of greatest length is the reverse permutation , having length . The basic question of Angel et al. is: what does a random reduced word for look like? We’ll look at two ways of visualizing a reduced word. First, think of a reduced word as a sequence of permutations:
For each entry , track its position in each permutation in the sequence. Since at each step we just switch two adjacent entries, positions change by at most 1 each time, so we can hope to get nice-looking piecewise curves. To be precise, for each , draw the path which connects the points
Here’s what you get, for (having drawn only some of the paths, to reduce clutter):

Are these… sine waves?
Let’s press on. Consider the same sequence of permutations
but now draw their graphs, as functions , in sequence. In the following picture we do that and then go back to the identity.

!!!
Angel et al. don’t quite prove that you get these sine wave and rotating disk pictures in the limit, but they do give an attractive geometric interpretation of reduced words which should explain the pictures, in terms of the permutahedron. Instead of that, though, I’ll talk about how one samples reduced words uniformly at random to create these pictures. This might not sound so exciting, but in fact leads to some rather nice mathematics.
The obvious thing to do to choose a reduced word for is start with , choose a random adjacent pair which isn’t an inversion, swap it, and repeat until you’re at . Unfortunately, this doesn’t give a uniform distribution (try it for ). To understand how Angel et al. solve this problem, we’ll go back to the 80s when Stanley was thinking about counting reduced words. First, however, we need some basics about symmetric functions.
Symmetric functions
A symmetric function is a formal power series in infinitely many variables, with integer coefficients, which remains unchanged under permutation of the variables: if , then . [We should also assume has terms of only finitely many different degrees, so that the ring of symmetric functions is graded by degree]. For example:
or
more generally, the elementary symmetric function , the sum of all squarefree degree monomials.
Here’s one reason to care about symmetric functions: they’re characters of -modules. Suppose is a finite-dimensional complex -module, and let be the subgroup of diagonal matrices in . To avoid awful things let’s assume is really a representation of as an algebraic group, meaning that the defining map is a map of varieties. Given with diagonal entries , the character of is . Basic representation theory (Schur’s lemma) shows this is a symmetric (Laurent^1) polynomial in .
For example, take , and a basis of . Any basis vector for is an eigenvector for , with eigenvalue . Now is the sum of all these eigenvalues, which is just the elementary symmetric function . It’s similarly easy to see that the character of is the homogeneous symmetric function
[The fact that we now just have finitely many variables can be safely glossed over.]
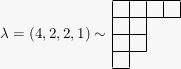
From this point of view, there are some obvious symmetric functions to look at: the characters of simple -modules. These turn out to be naturally indexed by partitions — finite integer sequences , where . Say is a partition of if . The Ferrers diagram of a partition is gotten by drawing a left-justified row of boxes for each , starting at the top and going down:
A semistandard tableau (plural tableaux) of shape is a filling of the boxes of the Ferrers diagram of with positive integers which is strictly increasing down columns, weakly increasing rightward across rows:
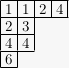
To a semistandard tableau , associate a monomial , the product of as ranges over the entries of the tableau. For the tableau above, this monomial is . Now given a partition , the Schur function is
where ranges over all semistandard tableaux of shape . It’s less than obvious from this definition that is symmetric, but it is. The Schur functions as runs over partitions with length at most turn out to be (almost^1) exactly the irreducible characters of .
Examples
If , a semistandard tableau of shape is a weakly increasing sequence . The Schur function is above, associated to .
If , a semistandard tableau of shape is a strictly increasing sequence , and , associated to .
If , there are 2 semistandard tableaux with entries at most 2,
and so . To locate the corresponding module, do a bit of algebra:
so the module should be .
One last fact that we’ll need, which follows from the realization of Schur functions as irreducible characters: as ranges over all partitions of , the Schur functions form a -basis of the degree symmetric functions.
Stanley symmetric functions
Let’s get back to reduced words. If is a partition of , meaning that , a standard tableau of shape is a semistandard tableau of shape with entries . For example, has two standard tableaux,
Stanley noticed the following coincidence: for , the number of reduced words for matches the number of standard tableaux of the staircase shape ; we’ve seen this for . The numbers are 1, 1, 2, 16, 768, 292864, so this is pretty convincing.
Now we define a somewhat mysterious-looking symmetric function. The Stanley symmetric function of a permutation is
where is the set of reduced words of , and is the set of integer sequences such that if , then . Here is the length of .
[Where does this come from? It seems plausible that Stanley was aiming for , for reasons which will become clear below, and already knew about similar “quasisymmetric” expansions for Schur functions.]
Example
Take , with reduced words . Then and , so
In this example is visibly symmetric, which is true in general, if not at all obvious.
Here’s the key enumerative fact. Right from the definitions we see that the coefficient of in is the number of standard tableaux of shape ; call it . On the other hand, for any reduced word , and so the coefficient of in is the number of reduced words of . So, if we write
then !
Of course this isn’t so useful without a reasonable way of getting at the Schur decomposition of . This post is long enough, so next time I’ll describe three such ways: one combinatorial (which will also solve the problem of sampling from uniformly), one representation-theoretic (since is a symmetric function, maybe it’s the character of some module???), and one based on the geometry of Schubert varieties.
Notes
1 Here “Laurent” and “almost” have the same explanation: the 1-dimensional representations of where acts as multiplication by for some positive integer .